There is an increasing need to collaborate between government agencies in developing models to look for better ways to provide the services their citizens need. Often this involves working with a lot of privacy sensitive data. And therefore there are a lot of (legal) issues in sharing these data sets and subsequently the models. I have been looking for ways to generate synthetic data sets with the same properties and structure as the real data sets but without the real rows of data. In this search, this article was very helpful: http://gradientdescending.com/generating-synthetic-data-sets-with-synthpop-in-r/. Based on this article I made a small demo and presented it to colleagues. The example here will use a generated data set for reproducibility.
library(tidyverse)
library(msm)
library(synthpop)
set.seed(20190518)
We will generate a couple of features and put them in a data frame. And perform some corrections. In some variables there will be missing values.
sex <- sample(c("M", "F", NA), 5000, replace = TRUE, prob = c(0.49, 0.5, 0.01))
age <- round(rtnorm(n = 5000, mean = 45, sd = 24, lower = 0, upper = 99))
income <- sample(c("High", "Middle", "Low", 9999999), 5000, replace = TRUE, prob = c(30, 40, 25, 5))
#Names of neighbourhoods in Nijmegen
neighbourhood <- sample(c("Wolfskuil", "Biezen", "Centrum", "Hatert", "Hunnerberg", "Altrade"), 5000, replace = TRUE, prob = c(0.15, 0.2, 0.1, 0.25, 0.15, 0.15))
married <- sample(c("Married", "Single"), 5000, replace = TRUE, prob = c(0.45, 0.55))
kids <- sample(c(0:4), 5000, replace = TRUE, prob = c(0.4, 0.3, 0.2, 0.08, 0.02))
df_og <- data.frame(sex, age, income, neighbourhood, married, kids) %>%
mutate(married = ifelse(age < 18, "Kid", married),
kids = ifelse(age < 18, 0, kids))
head(df_og, 2)
## sex age income neighbourhood married kids
## 1 M 74 Low Biezen 2 1
## 2 F 74 Middle Hatert 1 1
The missing values will be replicated in the synthesized data frame. We will also make sure no one under the age of 18 will be married or has kids in the synthesized data. To do that we will make a couple of lists that we will use later when we will synthesize the data.
rules <- list(married = "age < 18", kids = "age < 18")
rules_values <- list(married = "Kid", kids = 0)
missings <- list(sex = c(NA), income = c("9999999"))
With the definition of these rules done, we’re ready to synthesize our original (already fake) data.
df_synth <- syn(df_og, cont.na = missings, rules = rules, rvalues = rules_values, print.flag = FALSE)
##
## Variable(s): married have been changed from character to factor.
head(df_synth$syn)
## sex age income neighbourhood married kids
## 1 M 54 Middle Hunnerberg 1 1
## 2 M 93 Middle Hatert 2 1
## 3 M 52 Low Biezen 2 1
## 4 M 60 High Hunnerberg 1 3
## 5 F 71 Low Hatert 2 1
## 6 F 49 9999999 Altrade 1 2
The package contains a really convenient way to compare the synthesized and original data set. In these plots you can check if the distributions of the data are correct. You’ll see that the distributions are not totally the same, but very close. The rules we set are also nicely followed. No one under 18 is married or has any kids. great!
cmpr <- compare(df_synth, df_og, nrow = 2, ncol = 3)
cmpr$plots
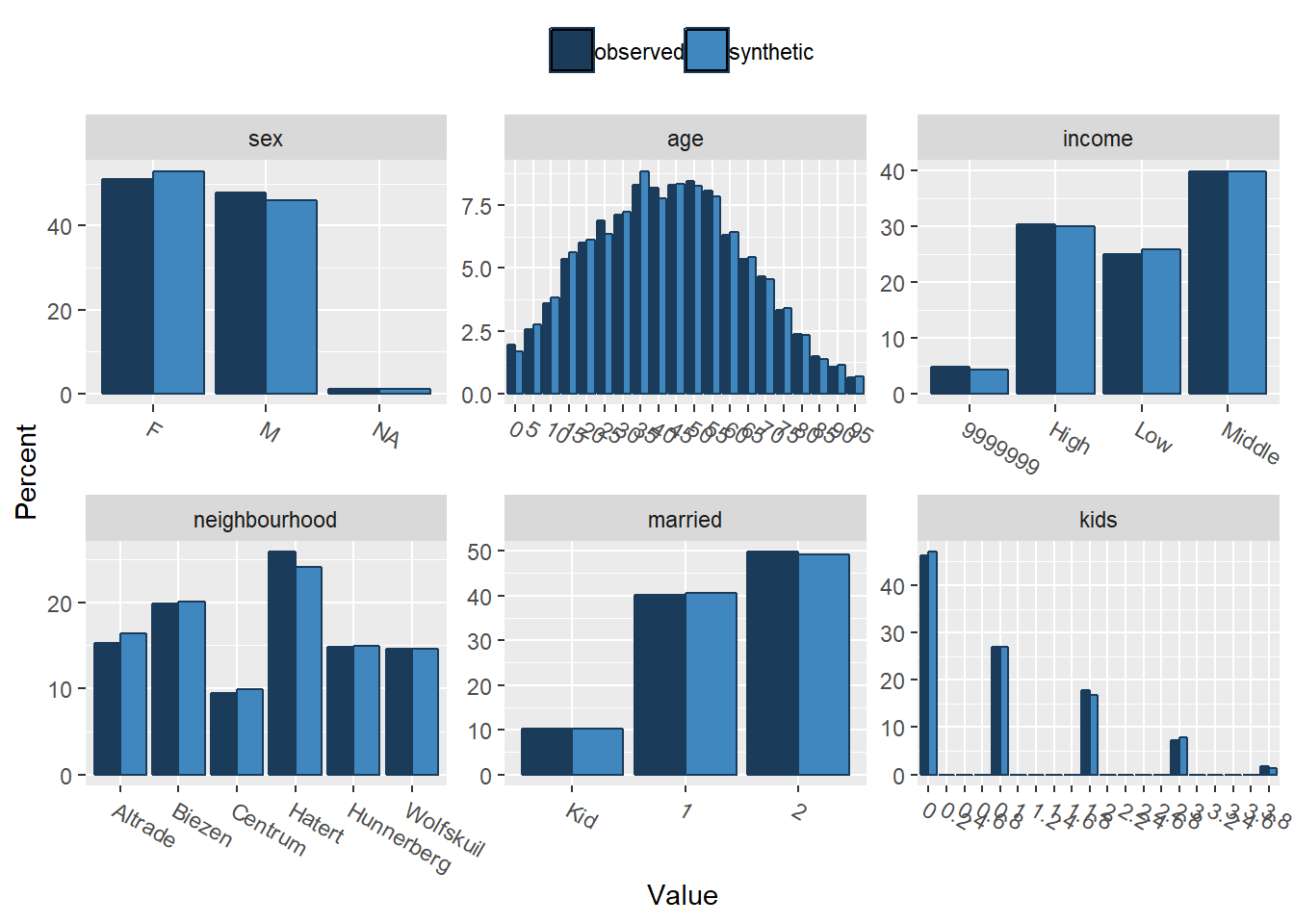
df_synth$syn %>% filter(age < 18) %>% count(married, kids)
## # A tibble: 1 x 3
## married kids n
## <fct> <dbl> <int>
## 1 Kid 0 510
The synthpop package is easy to use and does an overall good job of synthesizing data. This way of synthesizing data has a lot of potential to make sharing data about privacy sensitive matters easier and safer. For a more detailed overview of how the synthpop package works, look at the CRAN vignette: https://cran.r-project.org/web/packages/synthpop/vignettes/synthpop.pdf. For more complex and hierarchical datasets other packages might be required. For an overview of other options to synthesize (more complex) data, see : https://www.jstatsoft.org/article/view/v079i10.